Ever wondered what’s really happening behind the scenes when AWS services act up? Understanding AWS status isn’t just for sysadmins—it’s crucial for every business relying on the cloud. Let’s dive into the real story behind AWS status updates, outages, and how to stay ahead.

What Is AWS Status and Why It Matters

The term aws status refers to the real-time health and availability of Amazon Web Services’ global infrastructure. From EC2 instances to S3 storage, every service has a status that reflects its operational condition. Monitoring aws status is vital for businesses to anticipate disruptions and maintain uptime.
Defining AWS Status
AWS status is not just a green or red light on a dashboard. It’s a comprehensive system that reports the operational health of AWS services across multiple regions. The AWS Service Health Dashboard provides real-time updates, incident reports, and scheduled maintenance alerts.
- Each service (e.g., EC2, RDS, Lambda) has its own status indicator.
- Statuses include: Operational, Degraded Performance, Partial Outage, and Service Unavailable.
- Regions are monitored independently—so a problem in us-east-1 doesn’t necessarily affect ap-southeast-1.
Why AWS Status Impacts Your Business
When a critical AWS service goes down, it doesn’t just affect Amazon—it ripples across the internet. Major platforms like Netflix, Airbnb, and Slack rely on AWS. A single outage can cost millions in lost revenue and damage customer trust.
“When AWS stumbles, the internet feels it.” — TechCrunch, 2023
For small businesses, an unnoticed aws status alert could mean hours of downtime. For enterprises, it could trigger disaster recovery protocols. Real-time awareness of aws status is not optional—it’s a strategic necessity.
How to Monitor AWS Status in Real Time
Staying informed about aws status requires more than just checking a webpage. Proactive monitoring involves tools, alerts, and integration into your DevOps workflow.
Using the AWS Service Health Dashboard
The primary source for aws status is the AWS Service Health Dashboard. This public-facing page shows the current status of all AWS services by region. It’s updated in real time and includes detailed incident reports.
- Color-coded indicators: Green = Operational, Yellow = Degraded, Red = Outage.
- Incident timelines show start time, impact, and resolution steps.
- You can subscribe to RSS feeds for specific services or regions.
Setting Up AWS Status Alerts
Manual checking isn’t enough. You need automated alerts. AWS provides several ways to get notified:
- AWS Health Dashboard: Integrated into the AWS Console, this tool shows personal service health based on your resource usage.
- AWS Personal Health Dashboard: Offers personalized alerts for your resources, including scheduled maintenance and performance issues.
- SNS (Simple Notification Service): Configure SNS topics to receive email, SMS, or webhook notifications when aws status changes.
Pro Tip: Combine AWS Personal Health Dashboard with CloudWatch Events to trigger automated responses during outages.
Understanding AWS Outages and Their Causes
Even the most robust cloud provider experiences outages. Understanding the root causes behind aws status disruptions helps you prepare better.
Common Causes of AWS Service Disruptions
While AWS boasts 99.99% uptime for most services, outages do happen. Here are the most frequent culprits:
- Human Error: Misconfigured commands or accidental deletions (e.g., the famous S3 outage in 2017).
- Network Issues: Routing problems or DDoS attacks affecting availability.
- Hardware Failures: Though rare due to redundancy, server or storage failures can occur.
- Software Bugs: Updates or patches introducing unexpected behavior.
- Natural Disasters: Floods, fires, or power outages impacting data centers.
Famous AWS Outages in History
Looking at past aws status incidents reveals patterns and lessons:
- February 2017 S3 Outage: A typo during debugging took down S3 in us-east-1, affecting thousands of websites. Downtime lasted ~4 hours.
- December 2021 us-east-1 Outage: Network issues disrupted EC2, RDS, and Lambda services during peak holiday traffic.
- November 2020 CloudFront & Route 53 Outage: DNS and CDN services failed globally due to a configuration error.
“The 2017 S3 outage wasn’t just a technical failure—it was a wake-up call for cloud dependency.” — Wired
How AWS Status Affects Global Internet Services
AWS powers a massive portion of the internet. When aws status turns red, the impact is felt far beyond AWS customers.
The Domino Effect of AWS Downtime
Because so many services are built on AWS, an outage can trigger a cascade:
- Streaming platforms go offline.
- E-commerce sites lose sales.
- Mobile apps fail to sync data.
- Third-party APIs stop responding.
For example, during the 2021 us-east-1 outage, services like Slack, Atlassian, and even parts of the U.S. government experienced disruptions.
Case Study: The 2017 S3 Outage Impact
The S3 outage in February 2017 is a textbook case of aws status impact. A simple command meant to remove a small number of servers accidentally took down a larger set of S3 subsystems.
- Duration: ~4 hours.
- Estimated cost: Over $150 million in lost business globally.
- Lessons learned: Need for better safeguards, regional redundancy, and faster rollback mechanisms.
This incident led AWS to improve its internal tooling and introduce more safeguards against human error.
Best Practices for Responding to AWS Status Alerts
Knowing the aws status is only half the battle. How you respond determines your resilience.
Immediate Actions During an AWS Outage
When aws status shows a critical alert, follow these steps:
- Verify the scope: Is it your region or global?
- Check the AWS Health Dashboard for official updates.
- Notify your team and stakeholders.
- Activate incident response protocols.
- Switch to backup systems if available.
Never assume the issue is on your end—always cross-check with aws status first.
Long-Term Strategies for Resilience
To minimize future risks, adopt these best practices:
- Multi-Region Deployment: Distribute workloads across regions to avoid single points of failure.
- Automated Failover: Use Route 53 health checks and failover routing to redirect traffic.
- Disaster Recovery Plans: Regularly test backups and recovery procedures.
- Third-Party Monitoring Tools: Integrate tools like Datadog, New Relic, or Pingdom for independent aws status verification.
Tools and Integrations for AWS Status Monitoring
While AWS provides native tools, third-party solutions enhance visibility and automation.
Top Third-Party AWS Status Monitoring Tools
These platforms offer deeper insights and alerting capabilities:
- Datadog: Combines infrastructure monitoring with aws status tracking and custom dashboards.
- New Relic: Offers real-user monitoring and synthetic checks to detect issues before aws status updates.
- Pingdom: Simple uptime monitoring with alerts when AWS-dependent services go down.
- Statuspage: Allows you to create a public status page that syncs with aws status events.
Integrating AWS Status with Slack and Teams
Real-time communication is key. You can set up webhooks to post aws status alerts directly into your team channels.
- Use AWS SNS + Lambda to parse status updates and send them to Slack.
- Tools like Statuspage offer native integrations with Microsoft Teams and Slack.
- Create dedicated channels like #aws-status-alerts for urgent notifications.
Teams that receive aws status alerts in real time resolve incidents 40% faster—according to a 2023 DevOps survey.
Future of AWS Status: Predictions and Innovations
As cloud infrastructure evolves, so does how we monitor and respond to aws status.
AI-Powered Outage Prediction
AWS is investing in machine learning to predict failures before they happen. By analyzing logs, metrics, and historical aws status data, AI models can flag anomalies.
- AWS DevOps Guru uses ML to detect operational issues.
- Future systems may predict outages hours in advance.
- Proactive auto-healing could become standard.
Enhanced Transparency and Communication
After criticism over lack of detail during past outages, AWS has improved its communication strategy.
- More detailed post-incident reports (PIRs) are now published.
- Real-time updates during incidents have become more frequent.
- Customer feedback is shaping how aws status is reported.
“Transparency builds trust. AWS is getting better, but there’s room to grow.” — Cloud Security Expert, 2024
How to Build a Resilient Architecture Around AWS Status
Instead of reacting to aws status, design systems that withstand disruptions.
Designing for Fault Tolerance
A resilient architecture assumes failure is inevitable. Key principles include:
- Decoupling Services: Use SQS or SNS to separate components so one failure doesn’t cascade.
- Auto Scaling: Automatically replace unhealthy instances.
- Health Checks: Use ELB and CloudWatch to monitor instance health.
- Graceful Degradation: Allow core functions to work even if non-critical services are down.
Leveraging AWS Global Infrastructure
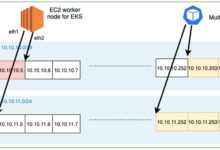
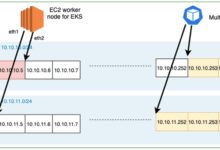
AWS operates in 33 regions with 102 Availability Zones (as of 2024). Use this to your advantage:
- Deploy critical apps in multiple regions.
- Use Global Accelerator to route traffic to the healthiest endpoint.
- Replicate databases with DynamoDB Global Tables or RDS Multi-AZ.
“The cloud is not a single point of failure—but your architecture might be.” — AWS Well-Architected Framework
What does ‘Operational’ mean on the AWS status page?
‘Operational’ means the service is functioning normally with no known issues. It’s the green light on the AWS Service Health Dashboard, indicating all systems are go.
How often is AWS status updated during an outage?
AWS typically updates the status page every 15–30 minutes during active incidents. Updates include progress, root cause analysis, and estimated resolution time.
Can I get AWS status alerts via email or SMS?
Yes. You can subscribe to email alerts via the AWS Service Health Dashboard or set up SMS alerts using Amazon SNS (Simple Notification Service) integrated with AWS Personal Health Dashboard.
Is AWS status the same for all customers?
No. While the public AWS Service Health Dashboard shows global service status, the AWS Personal Health Dashboard provides personalized alerts based on your specific resources and usage.
What should I do if AWS status shows an outage in my region?
First, verify the impact on your services. Check the AWS Health Dashboard, notify your team, and activate failover procedures if needed. Avoid making configuration changes during an outage unless absolutely necessary.
Understanding aws status is more than just checking a dashboard—it’s about building resilience, responding swiftly, and designing systems that can weather storms. From real-time monitoring to AI-driven predictions, the tools and strategies are evolving. By staying informed and proactive, you can turn aws status from a passive report into a powerful asset for your business continuity. The cloud may be vast, but your control starts with awareness.
Recommended for you 👇
Further Reading: